Working with data
7.1 Designing for data output
The primary objective of your Zooniverse project involves transforming an existing dataset (images of handwriting) into another form of dataset (lines and perhaps columns of text) that can be analyzed more efficiently to achieve the broader goals of your project. This transcription data may take on various forms depending on your plans for use. In this section, we’ll consider how your data can be processed, stored, analyzed, and shared during the course of your Zooniverse project and after it is completed.
Before creating your project, you should know what kind of data you want to collect. Your final data set will comprise a consensus for each Task in your Workflow for a given Subject. Keeping this in mind allows you to think of an ideal architecture for building your project and the provided tools to onboard your historical information to a usable digital dataset.
7.2 Data exports
7.2.1 How to export data from the Project Builder
You can request a data export via the Data Exports tab of the Project Builder. In this space, there are several types of data you can request.
| Export Type | Contents | Format |
|---|---|---|
| Classification export | all task data from all workflows for your entire project | JSON in CSV |
| Workflow classification export | all task data from a specific workflow | JSON in CSV |
| Workflow export | structural information about how your workflow looks, with version info | JSON in CSV |
| Subject export | a list of all subjects you have uploaded to the project, with any metadata included | JSON in CSV |
| Talk comment export | all comment data from Talk | JSON |
| Talk hashtag export | all hashtag data from Talk | JSON |
7.2.2 When to export data from the Project Builder
You can request a data export at any point, even if you have only submitted test transcriptions to your project. If you have not submitted any test transcriptions on your workflow(s), your classification data export will be empty. The Data Exports tab will also show when a Data Export was last requested for each export type.
7.2.3 How to export data from ALICE
For information on exporting data from ALICE, please refer to the ALICE documentation. Note that only ‘approved’ transcriptions can be exported from ALICE.
7.2.4 Data export examples
 Above: the header structure of a Project Builder workflow classification export. All examples below demonstrate the task-specific structure of data found in the
Above: the header structure of a Project Builder workflow classification export. All examples below demonstrate the task-specific structure of data found in the annotations column, unless otherwise noted.
This section will cover task types that are commonly used in Text Transcription projects. For information on other task types, please see the main 'How to create a project' documentation.
7.2.4.1 Question task (Project Builder export) - single response
This is the data export format for a question task where only a single response has been submitted, from the project Corresponding with Quakers:
{
"task":"T5",
"task_label":"What is the letter about? Choose a few keywords.",
"value":[
"health/illness/death"
]
}
In the above case, a volunteer has selected the option "health/illness/death" for the question What is the document about? Choose a few keywords.

7.2.4.2 Question task (Project Builder export) - multiple responses
This is the data export format for a question task where multiple choices are allowed, from the project Corresponding with Quakers:
{
"task":"T5",
"task_label":"What is the letter about? Choose a few keywords.",
"value":[
"letter writing/the post",
"family and friends"
]
}
In the above case, a volunteer has selected the options "letter writing/the post" and "family and friends" for the question What is the document about? Choose a few keywords.
This is what the task input area looks like for this specific example (i.e. what the volunteer sees when entering data):
7.2.4.3 Dropdown menu - single (Project Builder export)
This is the data export format for a single dropdown task, from the project Shadows on Stone: Identifying Sing Sing's Incarcerated:
{
"task":"T30",
"value":[
{
"select_label":"Relationship status",
"option":true,
"value":"6e68e5fc7071a",
"label":"Married"
}
]
}
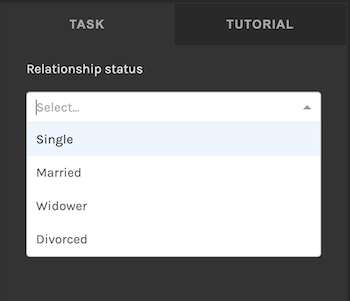
In the above case, a volunteer has entered "Married" into the "Relationship status" field via selecting an entry from the options provided in the dropdown list.
This is what the task input area looks like for this specific example (i.e. what the volunteer sees when entering data):
7.2.4.4 Dropdown menu - multiple (Project Builder export)
This is the data export format for three dropdown tasks, from the project Shadows on Stone: Identifying Sing Sing's Incarcerated, presented together in the same workflow step:
{
"task":"T52",
"task_label":null,
"value":[
{
"task":"T15",
"value":[
{
"select_label":"Sentenced (month)",
"option":true,
"value":3,
"label":"3 - March"
}
]
},
{
"task":"T16",
"value":[
{
"select_label":"Sentenced (day)",
"option":true,
"value":7,
"label":"7"
}
]
},
{
"task":"T17",
"value":[
{
"select_label":"Sentenced (year)",
"option":true,
"value":1898,
"label":"1898"
}
]
}
]
}
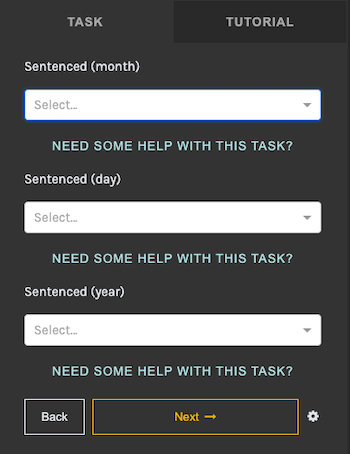
In the above case, a volunteer has entered "March" for Sentenced (month), "7" for Sentenced (day), and "1898" for Sentenced (year), meaning that, according to this record, this person was sentenced on March 7, 1898.
This is what the task input area looks like for this specific example (i.e. what the volunteer sees when entering data):
7.2.4.5 Free-text entry (Project Builder export)
This is the data export format for a free-text entry task, from the project Shadows on Stone: Identifying Sing Sing's Incarcerated:
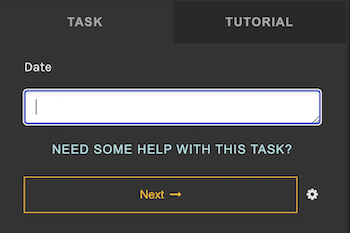
In the above case, a volunteer has entered "March 24, 1899" into the Date field provided.
This is what the task input area looks like for this specific example (i.e. what the volunteer sees when entering data):
7.2.4.6 Transcription Task (Project Builder export)
This is the Project Builder data export format for the Transcription Task, from the project Corresponding with Quakers. This is an example of what the first two lines of positional data look like when parsed:
[
{
"task":"T0",
"value":[
{
"x1":1460.4500246994899,
"x2":805.3800428124487,
"y1":96.11065371315667,
"y2":104.96295076568421,
"frame":0,
"details":[{"task":"T0.0.0"}],
"toolType":"transcriptionLine",
"toolIndex":0
},
{
"x1":1450.3331137823154,
"x2":1350.4286184752184,
"y1":166.92903013337732,
"y2":154.2828914869094,
"frame":0,
"details":[{"task":"T0.0.0"}],
"toolType":"transcriptionLine",
"toolIndex":0
},
... <continued>
]
}
]
This is an example of what the first four lines of text data look like when parsed:
[
...<continued>
{
"task":"T0.0.0",
"value":"Mountmelick 4th of 3rd mo",
"taskType":"text",
"markIndex":0
},
{
"task":"T0.0.0",
"value":"1811",
"taskType":"text",
"markIndex":1
},
{
"task":"T0.0.0",
"value":"My dear Aunt Sally,",
"taskType":"text",
"markIndex":2
},
{
"task":"T0.0.0",
"value":"Thou sent to know if I would",
"taskType":"text",
"markIndex":3
},
...<continued>
]
7.2.4.7 Transcription Task (ALICE Export)
This is the most basic of the ALICE data exports format (plain .txt) for the Transcription Task, from the project Corresponding with Quakers (first four lines of text only):
Mountmelick 4th of 3rd mo
1811
My dear Aunt Sally,
Thou sent to know if I would
This export version is only available after a subject is marked as Approved in ALICE. For more information on how to use ALICE, read the documentation.
7.3 Data aggregation
Because Zooniverse projects collect multiple transcriptions per Subject, you will need to have a plan for how to identify a single transcription that best represents the material you are transcribing. This could be through manual review, a ‘best of’ determination, scripted data aggregation methods, or other.
In this section we describe existing methods for aggregating data from text transcription projects.
7.3.1 Text aggregation with ALICE
The following images demonstrate text transcription data processing using ALICE. The first shows the aggregate line view for a given page, while the second shows the view for reviewing and editing an individual line of text.
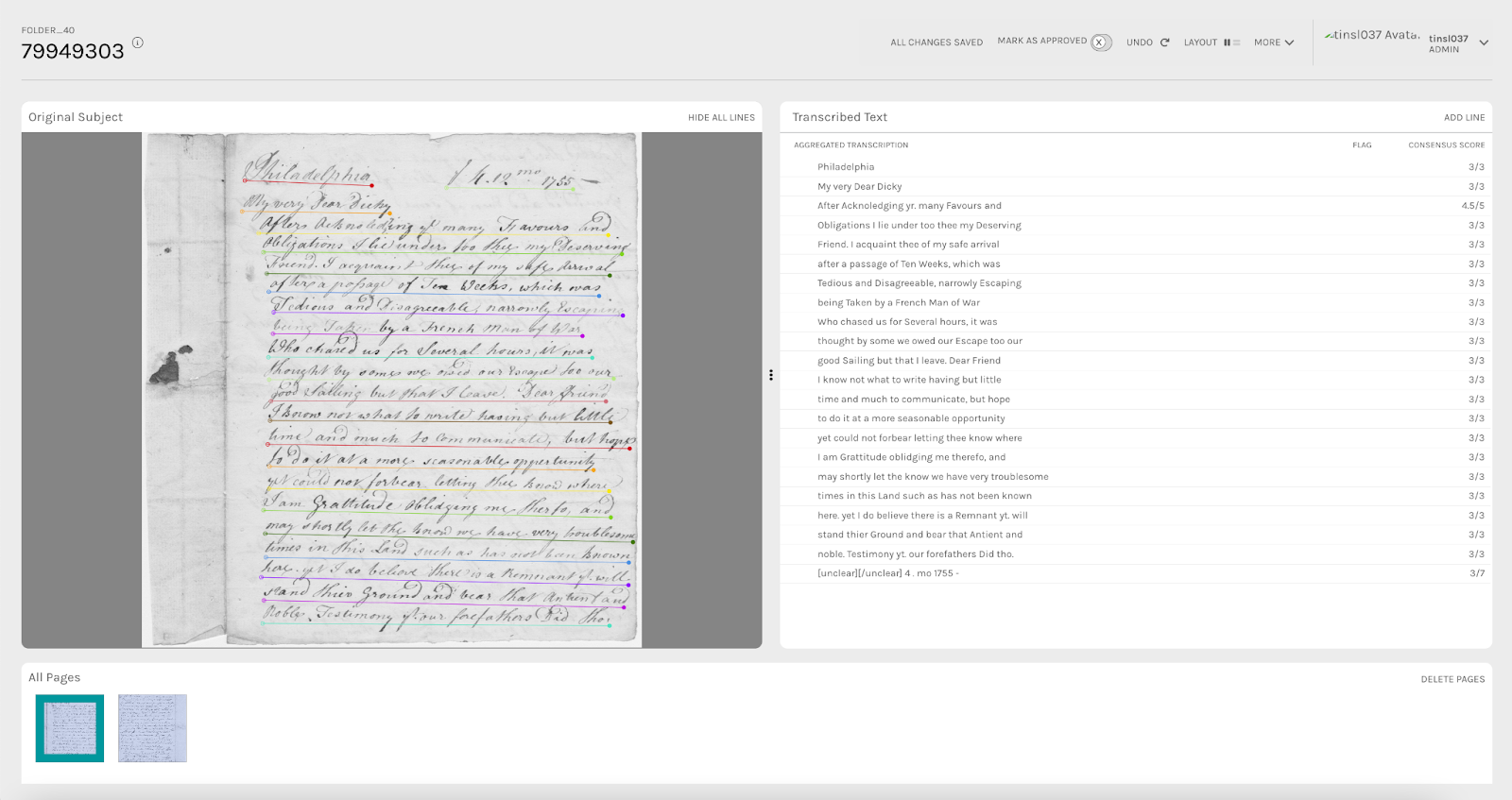 Above: Letter from John Peters, Dec. 4, 1755. University of California Santa Barbara Mss 4, Box 12, folder 40, 001. A screenshot from the ALICE interface for Corresponding with Quakers, Principal Investigator and Project Director Rachael Scarborough King.
Above: Letter from John Peters, Dec. 4, 1755. University of California Santa Barbara Mss 4, Box 12, folder 40, 001. A screenshot from the ALICE interface for Corresponding with Quakers, Principal Investigator and Project Director Rachael Scarborough King.
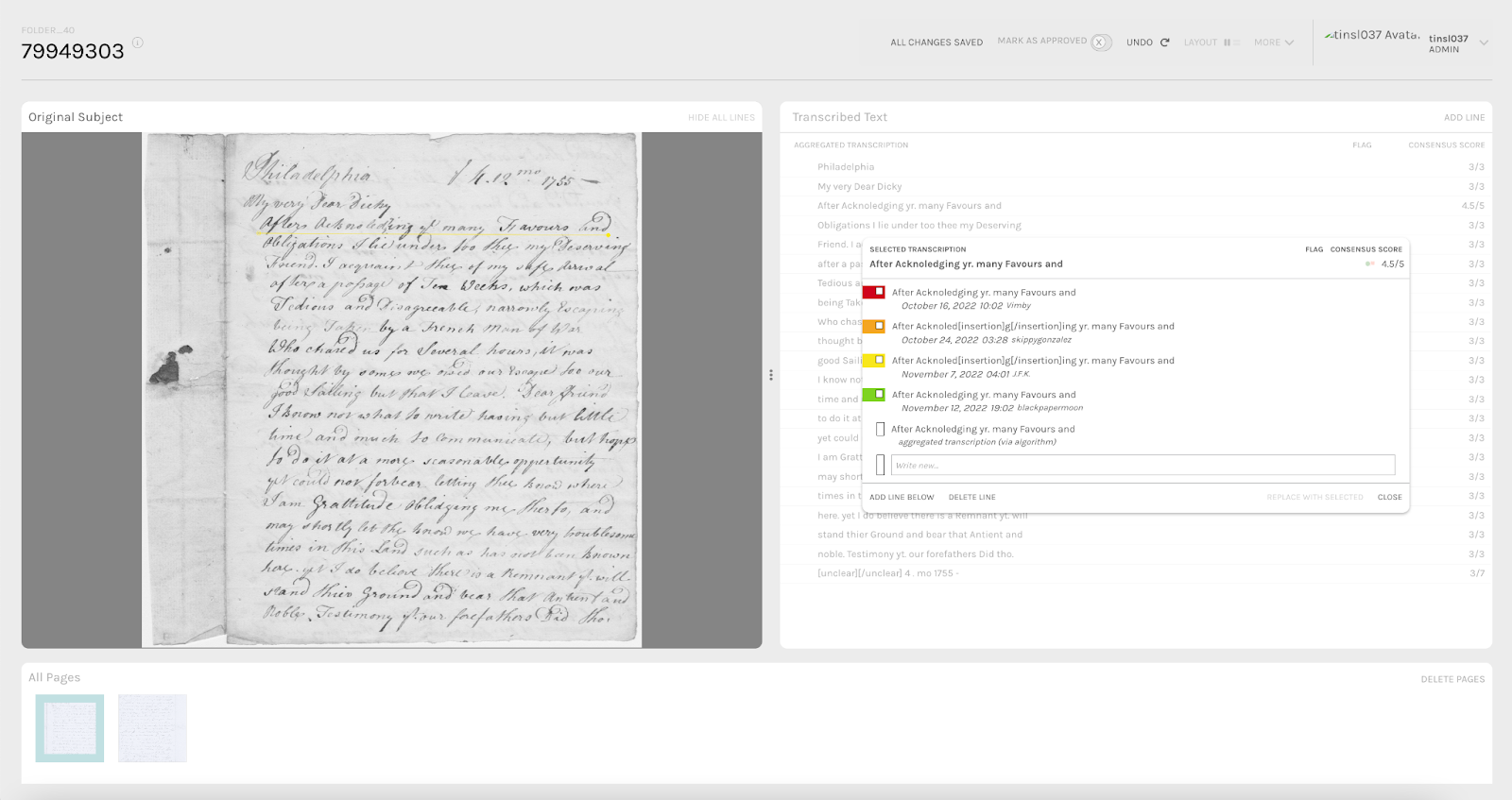 Above: Letter from John Peters, Dec. 4, 1755. University of California Santa Barbara Mss 4, Box 12, folder 40, 001. A screenshot from the ALICE interface for Corresponding with Quakers, Principal Investigator and Project Director Rachael Scarborough King.
Above: Letter from John Peters, Dec. 4, 1755. University of California Santa Barbara Mss 4, Box 12, folder 40, 001. A screenshot from the ALICE interface for Corresponding with Quakers, Principal Investigator and Project Director Rachael Scarborough King.
The Aggregated Line Inspector and Collaborative Editor (ALICE) is the main tool for researchers seeking to automate aggregation of multiple volunteer transcriptions into a single response. To use ALICE, you will need to be using the Transcription Task in your project to collect volunteer transcriptions. Please read through the comprehensive documentation about ALICE if you plan to use this tool, as there are restrictions on how to set up and build your project which require intervention from the Zooniverse team.
7.3.2 Other Task types
Zooniverse has a robust framework for aggregating data generated via other Task types (e.g. Question Tasks, Dropdown Tasks, etc.). The in-house code supports data aggregation for nearly all the Project Builder Task types, by providing tools to process and aggregate classification data exported from Zooniverse projects.
A general overview of this process would be: configuring Panoptes to your exported data, extracting the pertinent data from a classification export, and then reducing data for a given Task based on the consensus from each Task’s classification set.
For an example of Python data aggregation for a Question Task, see this notebook.
7.4 Data sharing requirement
Projects promoted to the Zooniverse community have the goal of producing useful research; your study needs to be well designed, and you must intend to analyze and write up your results as a formal publication. You must make volunteer classification data open within two years of a project’s completion. You also commit to communicating research findings to your volunteer community. Finally, you must formally acknowledge Zooniverse in any publications.
Please report publications using Zooniverse-produced data to us via this form.
7.5 Unexpected data
One of the benefits of a crowdsourced transcription project is that you are engaging with volunteers who come from a wide variety of backgrounds and fields. While you have a specific end-goal of using your classifications, there are many other, often unexpected outputs of a crowdsourced transcription project.
Talk boards provide one site where volunteers can share data or findings with one another and the research team. For example, the letters of Poets and Lovers often referenced specific paintings or pieces of art. Volunteers on the project took it upon themselves to look up digitized versions of the artworks mentioned and posted them on Talk. This not only provided a fantastic resource for volunteers who wanted to learn more about the two women authors of the diaries, but also the research team will try to incorporate these links into the published edition of the diaries. Talk boards can be exported from the ‘Data Exports’ tab of the Project Builder as a JSON for easier data analysis.
Case study: Poets and Lovers
Poets and Lovers is a project to transcribe the diary of Michael Field which was created by two women novelists Katharine Harris Bradley and Edith Emma Cooper.
Peter Logan, Principal Investigator:
The questions aren't hard and if I can't answer them, I tell one of my partners to get involved, and they'll know the answer. And some of the questions have been very interesting too. Some of them brought up things we didn't know about. So that was an unexpected outcome. We did actually learn things about what's in these diaries that we didn't know about. [The authors] talk a lot about paintings in the diaries, and I was going to write up [the volunteers] responses to the paintings. One of the volunteers found links to online images of the paintings, so we can incorporate them into the transcription. Which is exactly what we're going to do.
Project outputs are not limited to data. By virtue of the nature of crowdsourced transcription projects, research and data are opened up to more people. Many project teams have seen the engagement with the public as a vital output of their work, and have structured their research and project around that engagement. For example, the Mapping Prejudice team primarily worked with volunteers directly through meetings. They saw the work of educating people on the history of racial covenants through these in-person or small virtual events as an integral practice for their community work. Here, the process of crowdsourced transcription was as important of an output as the data.
7.6 Data curation
Depending on your affiliations, aspirations, and your project’s goals for presenting data, there may be several ways to preserve and share your project’s results. The most straightforward and cost-effective way for you as a researcher would be to utilize an affiliate institution's data repository (ones with the CoreTrustSeal are best). These institutional repositories allow for consistent access and long-term presentation of your data while allowing you to organize your data in a clear and detailed manner. If you are not a part of an institution, good options for preserving and publishing your data are the Open Science Framework and Dryad. In the social sciences, a widely used data repository is Open ICSPR.
Examples of successful data publications from Zooniverse projects can be found here: https://www.zooniverse.org/about/publications#data.